4.8 KiB
4.8 KiB
(简体中文|English)
websocket/grpc通信协议
本协议为FunASR软件包通信协议,分为离线文件转写(部署文档),实时语音识别(部署文档)
离线文件转写
从客户端往服务端发送数据
消息格式
配置参数与meta信息用json,音频数据采用bytes
首次通信
message为(需要用json序列化):
{"mode": "offline", "wav_name": "wav_name", "wav_format":"pcm", "is_speaking": True, "hotwords":"{"阿里巴巴":20,"通义实验室":30}", "itn":True}
参数介绍:
`mode`:`offline`,表示推理模式为离线文件转写
`wav_name`:表示需要推理音频文件名
`wav_format`:表示音视频文件后缀名,可选pcm、mp3、mp4等
`is_speaking`:False 表示断句尾点,例如,vad切割点,或者一条wav结束
`audio_fs`:当输入音频为pcm数据时,需要加上音频采样率参数
`hotwords`:如果使用热词,需要向服务端发送热词数据(字符串),格式为 "{"阿里巴巴":20,"通义实验室":30}"
`itn`: 设置是否使用itn,默认True
注:热词权重仅在fst热词服务下生效。
发送音频数据
pcm直接将音频数据,其他格式音频数据,连同头部信息与音视频bytes数据发送,支持多种采样率与音视频格式
发送音频结束标志
音频数据发送结束后,需要发送结束标志(需要用json序列化):
{"is_speaking": False}
从服务端往客户端发数据
发送识别结果
message为(采用json序列化)
{"mode": "offline", "wav_name": "wav_name", "text": "asr ouputs", "is_final": True,"timestamp":"[[100,200], [200,500]]","stamp_sents":[]}
参数介绍:
`mode`:`offline`,表示推理模式为离线文件转写
`wav_name`:表示需要推理音频文件名
`text`:表示语音识别输出文本
`is_final`:表示识别结束
`timestamp`:如果AM为时间戳模型,会返回此字段,表示时间戳,格式为 "[[100,200], [200,500]]"(ms)
`stamp_sents`:如果AM为时间戳模型,会返回此字段,表示句子级别时间戳,格式为 [{"text_seg":"正 是 因 为","punc":",","start":430,"end":1130,"ts_list":[[430,670],[670,810],[810,1030],[1030,1130]]}]
实时语音识别
系统架构图
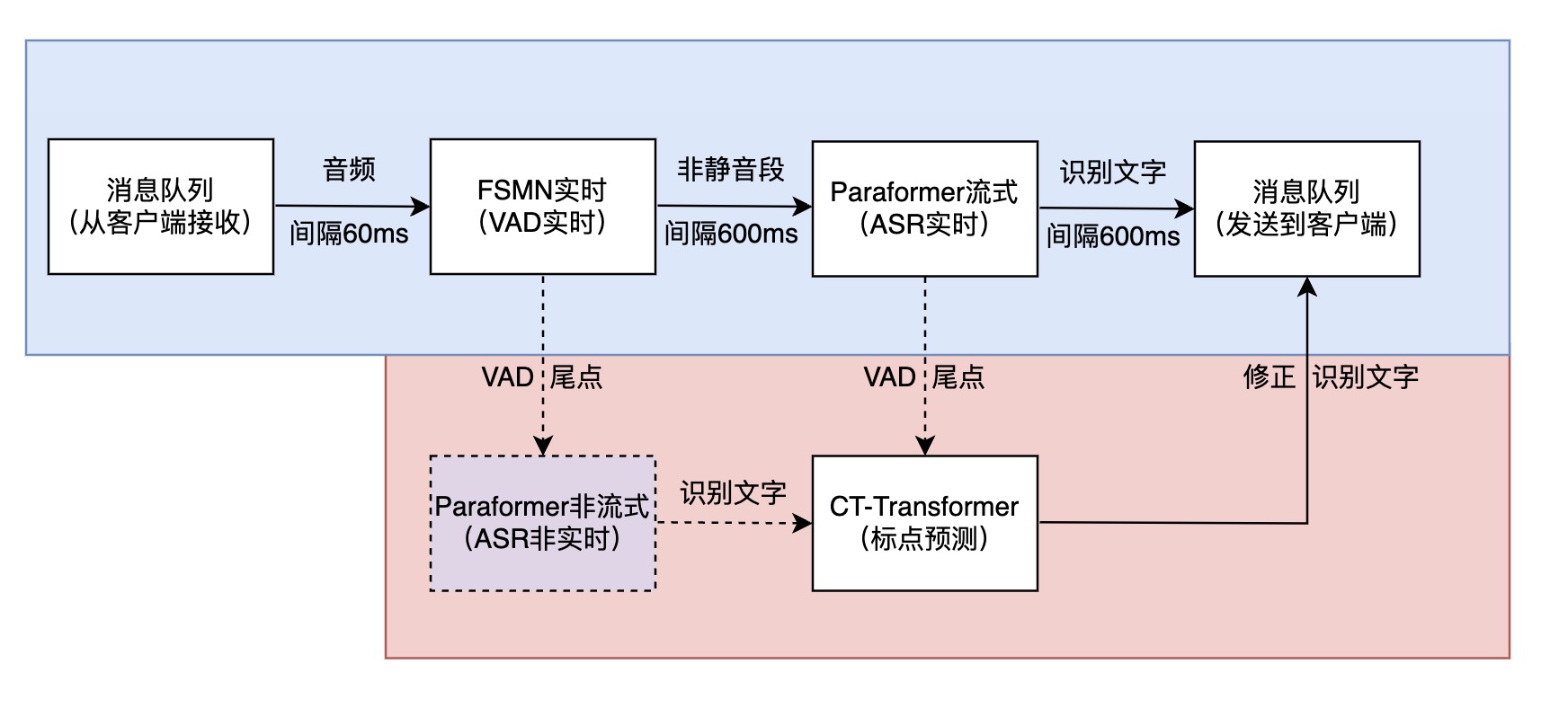
从客户端往服务端发送数据
消息格式
配置参数与meta信息用json,音频数据采用bytes
首次通信
message为(需要用json序列化):
{"mode": "2pass", "wav_name": "wav_name", "is_speaking": True, "wav_format":"pcm", "chunk_size":[5,10,5], "hotwords":"{"阿里巴巴":20,"通义实验室":30}","itn":True}
参数介绍:
`mode`:`offline`,表示推理模式为一句话识别;`online`,表示推理模式为实时语音识别;`2pass`:表示为实时语音识别,并且说话句尾采用离线模型进行纠错。
`wav_name`:表示需要推理音频文件名
`wav_format`:表示音视频文件后缀名,只支持pcm音频流
`is_speaking`:表示断句尾点,例如,vad切割点,或者一条wav结束
`chunk_size`:表示流式模型latency配置,`[5,10,5]`,表示当前音频为600ms,并且回看300ms,又看300ms。
`audio_fs`:当输入音频为pcm数据是,需要加上音频采样率参数
`hotwords`:如果使用热词,需要向服务端发送热词数据(字符串),格式为 "{"阿里巴巴":20,"通义实验室":30}"
`itn`: 设置是否使用itn,默认True
注:热词权重仅在fst热词服务下生效。
发送音频数据
直接将音频数据,移除头部信息后的bytes数据发送,支持音频采样率为8000(message中需要指定audio_fs为8000),16000
发送结束标志
音频数据发送结束后,需要发送结束标志(需要用json序列化):
{"is_speaking": False}
从服务端往客户端发数据
发送识别结果
message为(采用json序列化)
{"mode": "2pass-online", "wav_name": "wav_name", "text": "asr ouputs", "is_final": True, "timestamp":"[[100,200], [200,500]]","stamp_sents":[]}
参数介绍:
`mode`:表示推理模式,分为`2pass-online`,表示实时识别结果;`2pass-offline`,表示2遍修正识别结果
`wav_name`:表示需要推理音频文件名
`text`:表示语音识别输出文本
`is_final`:表示识别结束
`timestamp`:如果AM为时间戳模型,会返回此字段,表示时间戳,格式为 "[[100,200], [200,500]]"(ms)
`stamp_sents`:如果AM为时间戳模型,会返回此字段,表示句子级别时间戳,格式为 [{"text_seg":"正 是 因 为","punc":",","start":430,"end":1130,"ts_list":[[430,670],[670,810],[810,1030],[1030,1130]]}]