|
|
||
|---|---|---|
| .. | ||
| AliParaformerAsr | ||
| AliParaformerAsr.Examples | ||
| AliParaformerAsr.Examples.MauiApp | ||
| AliParaformerAsr.sln | ||
| README.md | ||
README.md
AliParaformerAsr
简介:
项目中使用的Asr模型是阿里巴巴达摩院提供的Paraformer-large ASR模型。 项目基于Net 6.0,使用C#编写,调用Microsoft.ML.OnnxRuntime对onnx模型进行解码,支持跨平台编译。项目以库的形式进行调用,部署非常方便。 ASR整体流程的rtf在0.03左右。
用途:
Paraformer是达摩院语音团队提出的一种高效的非自回归端到端语音识别框架。本项目为Paraformer中文通用语音识别模型,采用工业级数万小时的标注音频进行模型训练,保证了模型的通用识别效果。模型可以被应用于语音输入法、语音导航、智能会议纪要等场景。
Paraformer模型结构:
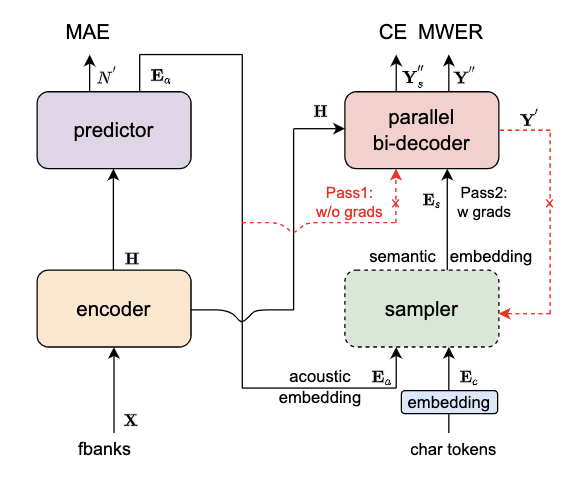
Paraformer模型结构如上图所示,由 Encoder、Predictor、Sampler、Decoder 与 Loss function 五部分组成。Encoder可以采用不同的网络结构,例如self-attention,conformer,SAN-M等。Predictor 为两层FFN,预测目标文字个数以及抽取目标文字对应的声学向量。Sampler 为无可学习参数模块,依据输入的声学向量和目标向量,生产含有语义的特征向量。Decoder 结构与自回归模型类似,为双向建模(自回归为单向建模)。Loss function 部分,除了交叉熵(CE)与 MWER 区分性优化目标,还包括了 Predictor 优化目标 MAE。
其核心点主要有:
Predictor 模块:基于 Continuous integrate-and-fire (CIF) 的 预测器 (Predictor) 来抽取目标文字对应的声学特征向量,可以更加准确的预测语音中目标文字个数。 Sampler:通过采样,将声学特征向量与目标文字向量变换成含有语义信息的特征向量,配合双向的 Decoder 来增强模型对于上下文的建模能力。 基于负样本采样的 MWER 训练准则。 更详细的细节见:
论文解读:Paraformer: 高识别率、高计算效率的单轮非自回归端到端语音识别模型
ASR常用参数(参考:asr.yaml文件):
用于解码的asr.yaml配置参数,取自官方模型配置config.yaml原文件。便于跟进和升级。
paraformer-large offline onnx模型下载
https://huggingface.co/manyeyes/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx
离线(非流式)模型调用方法:
1.添加项目引用
using AliParaformerAsr;
2.模型初始化和配置
string applicationBase = AppDomain.CurrentDomain.BaseDirectory;
string modelName = "speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx";
string modelFilePath = applicationBase + "./"+ modelName + "/model_quant.onnx";
string configFilePath = applicationBase + "./" + modelName + "/asr.yaml";
string mvnFilePath = applicationBase + "./" + modelName + "/am.mvn";
string tokensFilePath = applicationBase + "./" + modelName + "/tokens.txt";
AliParaformerAsr.OfflineRecognizer offlineRecognizer = new OfflineRecognizer(modelFilePath, configFilePath, mvnFilePath, tokensFilePath);
3.调用
List<float[]> samples = new List<float[]>();
//这里省略wav文件转samples...
//具体参考示例(AliParaformerAsr.Examples)代码
List<string> results_batch = offlineRecognizer.GetResults(samples);
4.输出结果:
欢迎大家来体验达摩院推出的语音识别模型
正是因为存在绝对正义所以我们接受现实的相对正义但是不要因为现实的相对正义我们就认为这个世界没有正义因为如果当你认为这个世界没有正义
非常的方便但是现在不同啊英国脱欧欧盟内部完善的产业链的红利人
he must be home now for the light is on他一定在家因为灯亮着就是有一种推理或者解释的那种感觉
after early nightfall the yellow lamps would light up here in there the squalid quarter of the broffles
elapsed_milliseconds:1502.8828125
total_duration:40525.6875
rtf:0.037084696280599808
end!
处理长音频,推荐结合AliFsmnVad一起使用:https://github.com/manyeyes/AliFsmnVad *
其他说明: 测试用例:AliParaformerAsr.Examples。 测试环境:windows11。 测试用例中samples的计算,使用的是NAudio库。