2.4 KiB
Baseline
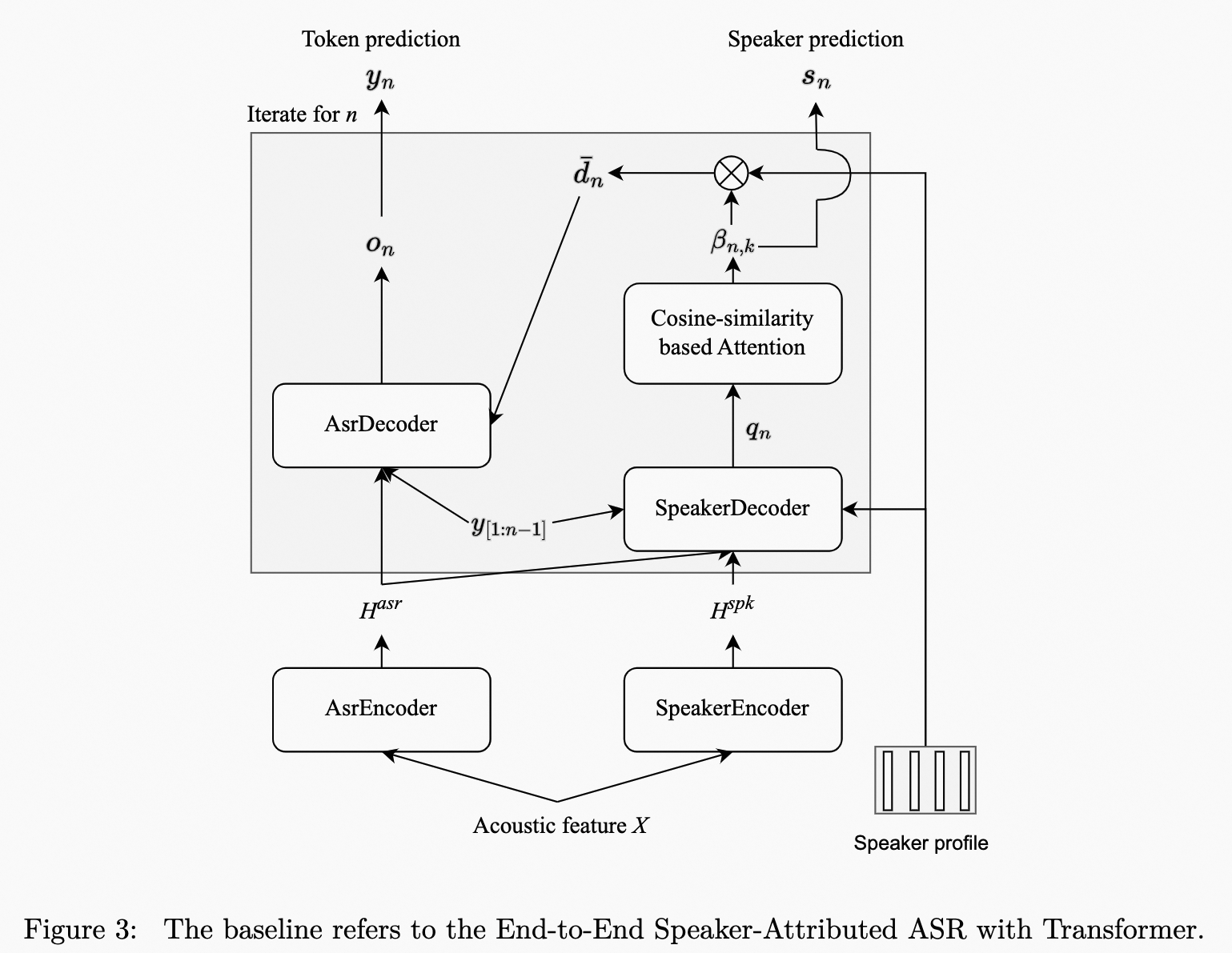
Overview
We will release an E2E SA-ASR baseline conducted on FunASR at the time according to the timeline. The model architecture is shown in Figure 3. The SpeakerEncoder is initialized with a pre-trained speaker verification model from ModelScope. This speaker verification model is also be used to extract the speaker embedding in the speaker profile.
Quick start
To run the baseline, first you need to install FunASR and ModelScope. (installation)
There are two startup scripts, run.sh for training and evaluating on the old eval and test sets, and run_m2met_2023_infer.sh for inference on the new test set of the Multi-Channel Multi-Party Meeting Transcription 2.0 (M2MeT2.0) Challenge.
Before running run.sh, you must manually download and unpack the AliMeeting corpus and place it in the ./dataset directory:
dataset
|—— Eval_Ali_far
|—— Eval_Ali_near
|—— Test_Ali_far
|—— Test_Ali_near
|—— Train_Ali_far
|—— Train_Ali_near
Before running run_m2met_2023_infer.sh, you need to place the new test set Test_2023_Ali_far (to be released after the challenge starts) in the ./dataset directory, which contains only raw audios. Then put the given wav.scp, wav_raw.scp, segments, utt2spk and spk2utt in the ./data/Test_2023_Ali_far directory.
data/Test_2023_Ali_far
|—— wav.scp
|—— wav_raw.scp
|—— segments
|—— utt2spk
|—— spk2utt
For more details you can see here
Baseline results
The results of the baseline system are shown in Table 3. The speaker profile adopts the oracle speaker embedding during training. However, due to the lack of oracle speaker label during evaluation, the speaker profile provided by an additional spectral clustering is used. Meanwhile, the results of using the oracle speaker profile on Eval and Test Set are also provided to show the impact of speaker profile accuracy.
| SI-CER(%) | cpCER(%) | |
|---|---|---|
| oracle profile | 32.72 | 42.92 |
| cluster profile | 32.73 | 49.37 |